The problem of visual object detection, as generally understood, is distinct from image recognition. In image recognition, an image as a whole is classified into one (or several) of a number of classes. In visual detection, on the other hand, the detector picks up the one or several instances of an object in the image and provides information about their position in the image, typically using rectangular bounding boxes.
There are several well-known datasets for visual object detection, but currently the common practice in the field is to benchmark methods using the COCO dataset, which contains more than 200 000 labelled images with about 1.5 million object instances belonging to 80 different classes [coco].
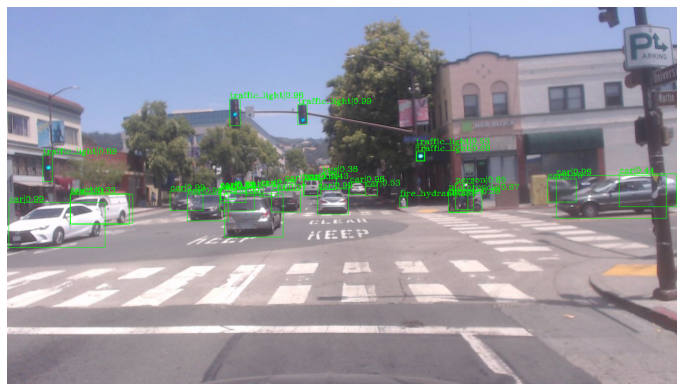
The results of a YOLOv3 detector trained on COCO when applied to a traffic image.
Literature
- [coco] COCO: Common Objects in Context. https://cocodataset.org/#home