In mathematical analysis, the gradient is a vector, which indicates the direction of the steepest ascent for a function at a given point. The idea of gradient-based optimization methods is to compute the gradient and move in the opposite direction: that of the steepest descent.
Let us suppose that the function we are trying to minimize is a paraboloid such as:

An instance of a convex function to be minimized.
For the paraboloid shown in the figure, the gradients would look as follows, i.e. they point outwards, in the direction of growth.
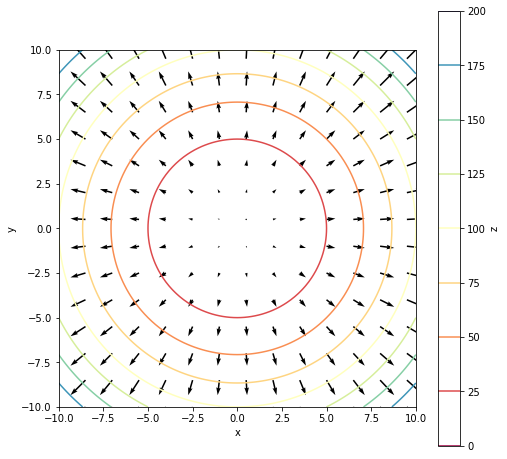
The gradients on a paraboloid.
It is then obvious why going in the direction opposite to the gradient, would minimize the function. An example of how a gradient-based method might gradually converge to the minimum of a function, is shown here:
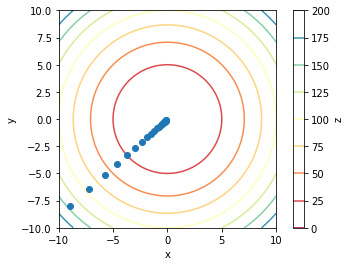
Gradient descent on a paraboloid.
Unfortunately, gradient – while being a valuable indicator – also has some negative properties, e.g. approaches using the raw gradient will have trouble with function that are not equally steep in all directions: gradient descent will either be extremely slow to converge for such functions, or else it will oscillate or even diverge:
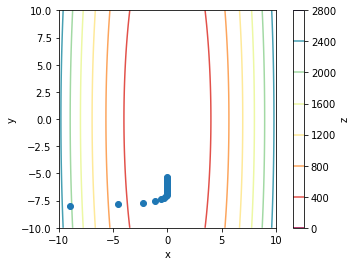
Gradient descent: slow convergence.

Gradient descent: divergence.
This is why a number of more sophisticated methods have been developed, which still use the gradient, but they guard against these effects in various ways: one popular approach is to add a momentum term, which can dampen oscillations.
Another advanced class of methods performs higher-order optimization: this means that they also use higher derivatives – typically only the second derivative. These methods have more information about the function than first-order methods: they are able to track how fast the gradient itself is changing and they also have information about interactions between different dimensions. This makes them much more effective than first-order methods.
However, higher-order methods can typically only be applied to relatively small problems, where the number of parameters is not too large. They are too expensive for problems like training a neural network with millions of parameters (if they can be applied at all, a single step takes so long that a first-order method is able to take a much larger number of steps in the same amount of time and actually outperform the higher-order method).