Reinforcement learning is another learning paradigm beside supervised learning and unsupervised learning. A reinforcement learning system receives feedback, but it does not come in the form of the desired outputs for each input. Reinforcement learning is used to solve sequential decision making problems, i.e. problems where an agent takes successive actions over time. In such scenarios desired outputs are typically not easy to specify, but we are often able to evaluate the performance of the agent based on whether it is performing its task or not. We can use this to evaluate/punish the agent using a reward signal: and this is the kind of feedback that reinforcement learning uses.
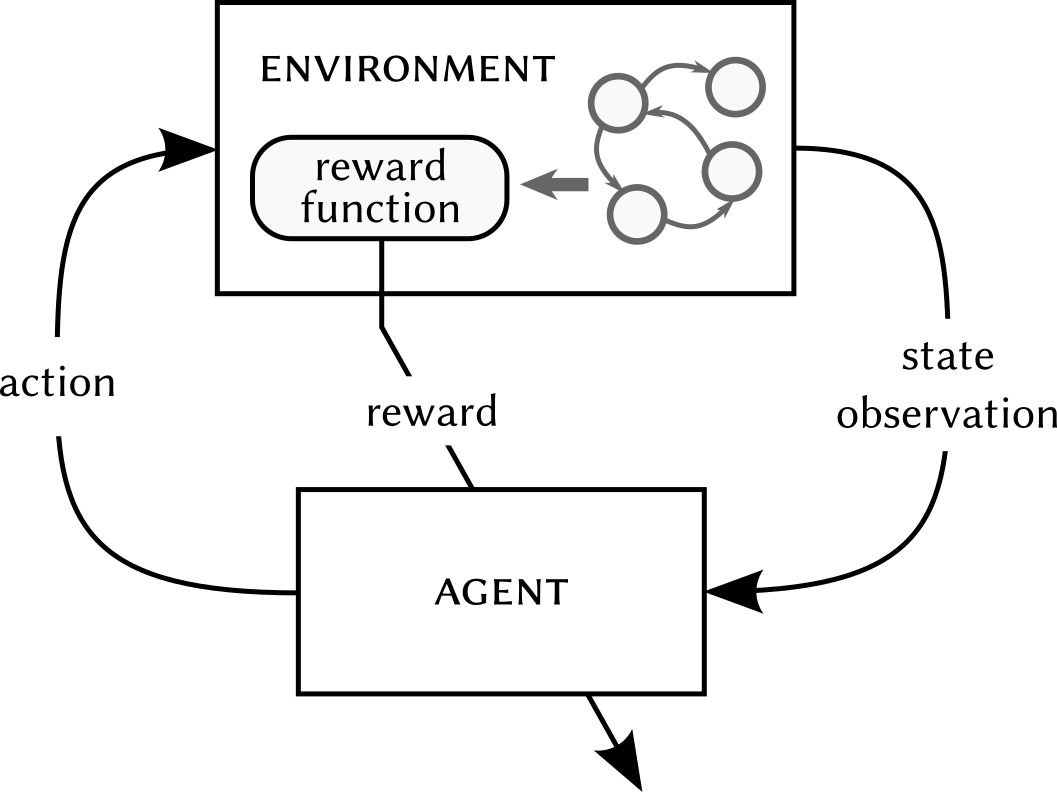
Reinforcement learning: the principle.
As shown in the figure, the reinforcement learning agent receives a state observation, uses it to determine the action, which it then applies. As a result, the state of the environment changes and the agent receives its immediate reward for performing the action.
The goal of a reinforcement learning agent is to maximize the rewards. However, this maximization needs to take into account the entire sequence of rewards: maximizing the immediate reward in the next step is not equivalent to maximizing the total reward received. An agent will often have to sacrifice some immediate rewards to maximize its rewards overall.
There are several reinforcement learning paradigms:
- Value-based methods: The agent learns a value function from experience, which predicts what long term rewards can be expected after taking a particular action in a particular state. It can then compute values for all available actions and choose the one with the greatest expected rewards. Methods of this kind include e.g. Q-learning and SARSA, or the Deep Q Network (DQN), which is a deep learning version of Q-learning.
- Policy-based methods: Policy-based methods represent the agent’s policy explicitly: e.g. by mapping the current state to an action using a neural network. This is especially advantageous in the case of a large or continuous action space, where it is not possible to iterate over all actions and compute their values. To train the policy, the agent can run it until the end of an episode (when the task ends or the agent runs out of time), measure the actual total rewards and use those to modify the policy. However, since both environments and agents have stochastic elements, each episode can play out differently and there can be a lot of noise in those total rewards, which makes learning difficult. Various versions of the REINFORCE method represent examples of policy-based approaches.
- Actor-critic methods: Actor-critic methods combine an actor (a policy) and a critic (a value function), thus uniting the value-based and the policy-based view and combining the best of the two worlds. Policies are still represented explicitly, but they can now be trained using values from the value function as opposed to the noisy samples of total rewards used by REINFORCE-like approaches. Modern actor-critic methods include e.g. the Soft Actor-Critic (SAC).