Deep learning is currently one of the most rapidly developing areas of artificial intelligence and machine learning. It is an area concerned with deep neural networks, i.e. artificial neural networks with many layers of neurons.

An artificial neural network.
An artificial neuron is an extremely simplified mathematical model of a biological neuron. An artificial neuron of the kind most commonly used today takes in n inputs, each multiplied by some weight (which determines the degree of influence that each input has on the neuron) and then sums them up to compute its inner potential. This inner potential is then mapped to the neuron’s output using some activation function.
It can be shown that a neural network with at least two layers of neurons with non-linear activation functions is a universal approximator: it can learn to approximate any function with a finite number of discontinuities to an arbitrary finite degree of precision [krose].
Deep Neural Networks
Deep neural networks, i.e. neural networks with many layers have one key property that has recently brought them to the forefront of machine learning: they are able to automatically learn how to preprocess unstructured data such as images, audio or natural language. Historically, when a standard (shallow) machine learning system would be applied to a task that involved unstructured data, some preprocessing procedure would have had to be designed. Through this procedure, the important features of the input data would be extracted and based on these, the machine learning system would be able to make its predictions.
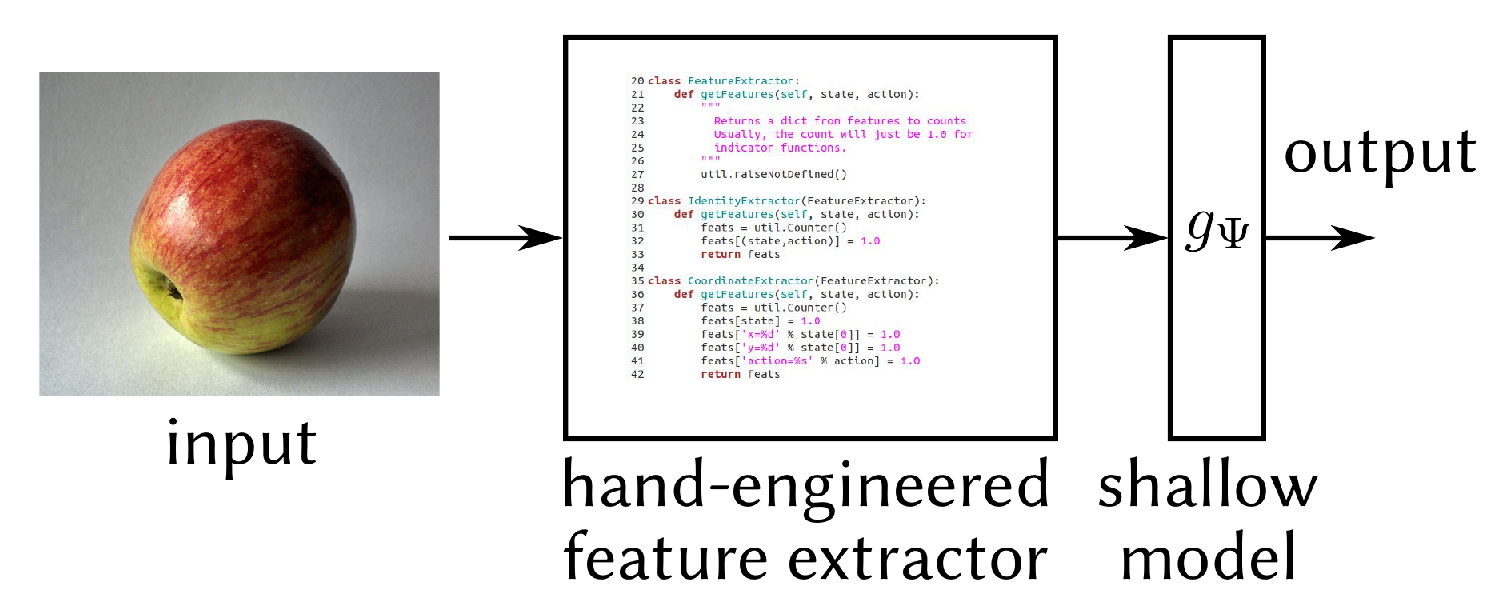
Classical machine learning with manual feature extraction.
The problem with this approach is that it is generally extremely difficult to design a good preprocessing procedure. Decades of research have been spent on feature engineering for domains such as image recognition and audio recognition and the results were still very far from perfect. In contrast, deep learning can learn to extract features automatically: it can use some of its initial layers to do this and then use the extracted features in the remaining few layers to compute its prediction.

Deep learning: a deep neural network learns to extract its own features.
Convolutional Layers
In order for deep learning to be effective, the architecture of the neural network needs to have useful inductive preferences: it needs to encode some prior knowledge about the problem. Otherwise the millions of parameters that a deep neural network can have would require unrealistically large amounts of data to be trained.
Among the best-known architectural elements of this kind are convolutional layers, which are used in image-related tasks. In an image, the same kind of object can occur at different positions and the key insight is that the neural network should not have to learn to detect it at every one of those positions separately: that would be extremely wasteful and difficult. Instead, if the neural network has learnt how to detect a rubber duck, it should be able to detect it no matter where it is in the image.
The idea behind convolutional layers is that the same detector (artificial neuron) slides over the entire image so that it can detect the feature it is focusing on wherever it occurs. In this way the detector produces what we call a feature map: a 2D array that, roughly speaking, indicates whether the feature was present. At every convolutional layer, there are many such detectors and many resulting feature maps, which are then stacked together (similarly to colour channels in an image) and passed to the next layer.

A convolutional feature detector sliding over an image.
Literature
- [krose] Kröse, B., Krose, B., van der Smagt, P. and Smagt, P., 1993. An introduction to neural networks.
- [goodfellow] Goodfellow, I., Bengio, Y., Courville, A., 2016. Deep learning. Cambridge: MIT press.