The task of cluster analysis involves identifying clusters (groups) of points in a dataset. The principal characteristic of a cluster is that its points are much closer to each other (in some sense: usually based on a well-defined distance measure) than they are to points outside the cluster.

Cluster analysis: an illustration.
Cluster analysis (or simply clustering) is unsupervised: it is distinct from a classification task in that no correct assignment of points into clusters is known beforehand. Clustering is frequently used in data analysis: often during exploratory analysis to get a sense of how the dataset is structured. It is also used in many practical applications – and its advanced forms that benefit from deep learning can handle unstructured data such as images, which leads to advanced applications such as face clustering in photo-management applications.



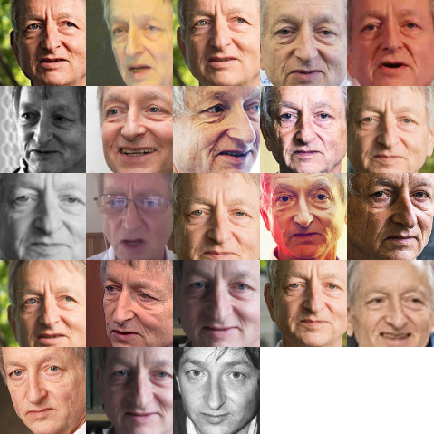
A face clustering produced using a deep face embedding and DBSCAN clustering.