The k-means algorithm is one of the simplest and most straight-forward clustering methods. In its name k refers to the number of clusters, which is a hyperparameter that needs to be specified beforehand; means refers to the way the clusters are represented – by their centres, which are computed as the empirical mean of the points in the cluster.
In k-means, the first step is to initialize the centres of these clusters, which can be done e.g. by selecting from among the points uniformly randomly (although there are more sophisticated ways, which are more robust).
The algorithm then simply alternates between two steps: (i) every point is assigned to a cluster by finding the closest cluster centre; (ii) cluster centres are updated to the average (empirical mean) of the points that now belong to the cluster. This process goes on until the point assignments have stabilized. The procedure is illustrated visually below.
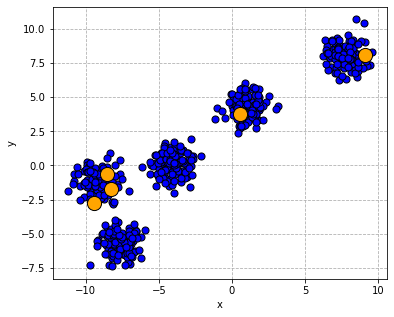
k-means: randomly initialized cluster centroids.
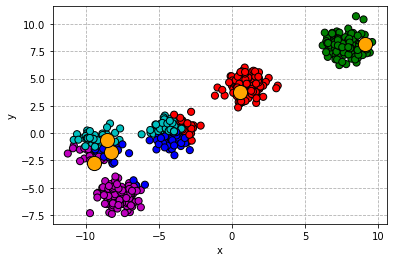
k-means: assignment to cluster.
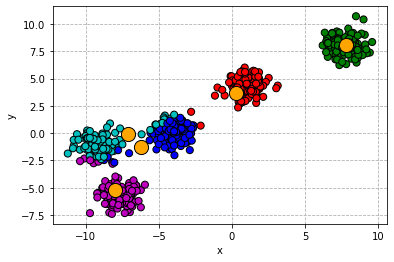
k-means: updating cluster centroids.


k-means: repeat until assignments to clusters stabilize.